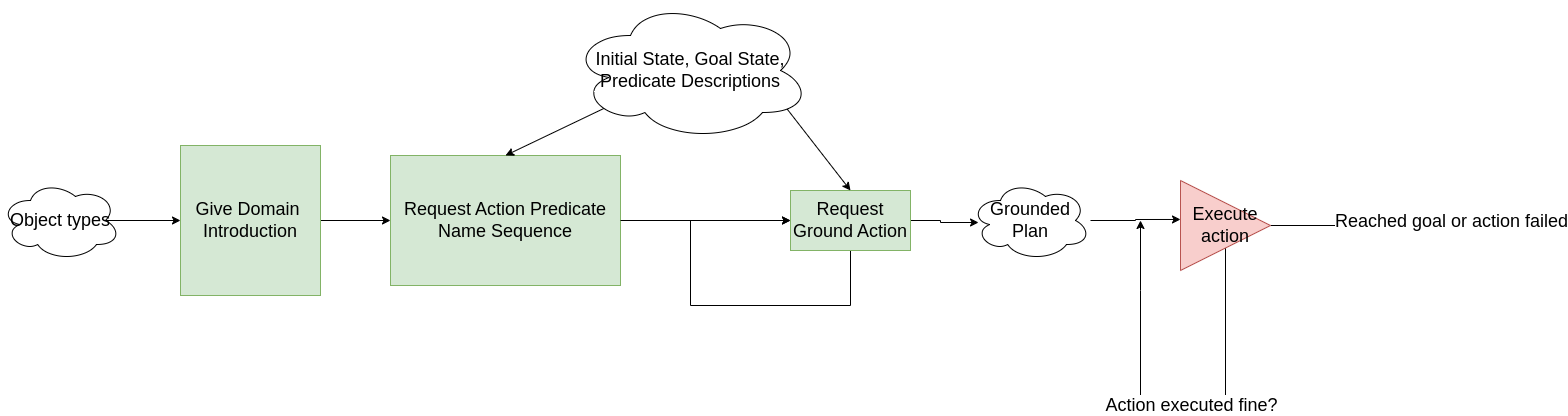
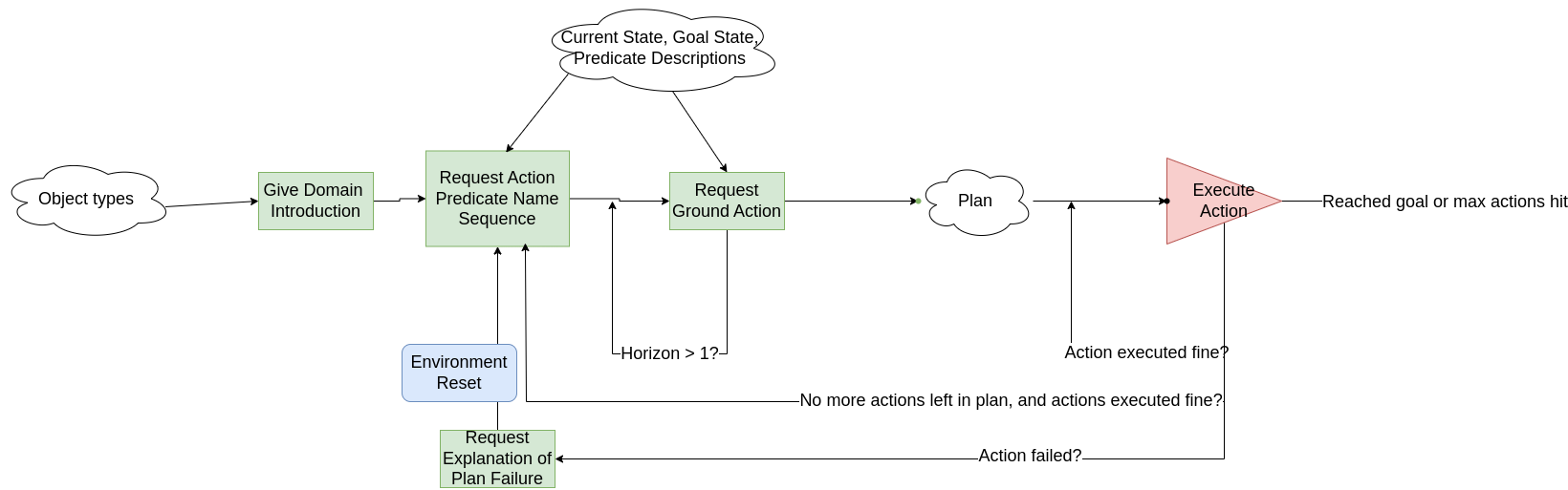
Prompt Templates
In the following sections, we detail the specific prompts and prompt templates used for each stage in both workflows.
Domain Introduction Prompts
At the beginning, we prompt twice, appending GPT4o's responses to our conversation each time. Here is the first prompt:
You are a household robot in a kitchen. You are in front of the kitchen counter, where there are some prepared ingredients.
More specifically, you will be given a set of facts that are currently true in the world, and a set of facts that is your goal to make true in the world. With my step-by-step guidance, you will think through how to act to achieve the goal.
Here is the second prompt:
In the kitchen, there different kinds of objects that you can interact with. The different kind of objects that you see are categorized into the following:
container
measuring cup
dessert
powder
butter
mixture
egg
oven
spatula
electric stand mixer
Right now, you see the some of these ingredients and items on the counter. You also see some appliances in the kitchen.
To start making a mixture for a souffle, you need to mix together egg yolk, sugar, butter, and a little bit of flour. To make a mixture for a cake, you need to mix together a whole egg, sugar, butter, more flour, and baking powder.
Requesting Action Sequence Prompt Templates
We first prompt with the starting state using this template:
f"""
The following things are true at this moment:
{starting_state_predicate_fstrings}
As a reminder, in the kitchen, the pans, measuring cups, and bowls are on the counter, and the oven(s) is (are) behind the counter. If you are baking desserts, please rationalize what are the essential ingredients and their amounts to make those desserts and use only those. Once an ingredient is used once, it can't be reused.
You should have all of the ingredients that you need on the counter prepared for you. I'll let you know what desserts you will make shortly.
"""
Then, we prompt with the goal state and the defined set of actions for the robot:
f"""These are the things that you would like to become true:
{goal_state_predicate_fstrings}
This state is your goal.
These are the names of the atomic actions that we can perform, along with their descriptions:
{action_description_string}
Can you please give a sequence of these phrases that will get us to the goal? Include the exact phrase in each step of your answer. Format it using a numbered list with one line per step, starting with "1.". Give a little explanation of each step underneath each bullet point. Mark the end of the plan with '***' in your response. Please avoid any past planning mistakes.
"""
Grounding Action Prompt Templates
For the first action we ground, we prompt using this template:
f"""Thanks. Let's think step by step what objects are associated with each of these actions.
Let's recap what we've talked about. Currently, the following facts are true:
{starting_state_predicate_fstrings}
We want to make these facts true:
{goal_state_predicate_fstrings}
We're thinking through a plan step-by-step to our goal.
We are about to do the next step in the plan:
{instruction}
""" + \
"""We need to identify the names of the specific objects involved in this action. Here are more details about how the objects involved need to relate to the action.
""" + '\n'.join(variable_description_list)
For the following actions in the action sequence from the LLM that we ground, we use only the second
half of the above template (starting from "We are about to do the next step in the plan:").
To ground each variable in the action predicate referenced by the name in the action sequence from the
LLM, we use this prompt template:
f"""We are going to {action_description_with_nonspecific_articles[:-1].lower()}. Given knowledge of the current state and our planned actions, which of the following objects fits the description, {variable_description}?
""" + '\n'.join([o._str.split(':')[0] for o in objects_list]) + '\n' + 'Please explain your answer, and then answer with the object name on the last line after "Answer:".'
Plan Failure Explanation Prompt Templates
We first prompt with this prompt template to request an explanation about the plan failure:
f"""Based on your plan, we've just executed these actions:""" + executed_plan_string + \
f"""However, the last action failed to execute properly. Before we executed the last action, the following facts were true in the environment:
{state_description}
Then, we tried executing this action:
{last_action_description}
However, executing this action failed. Please explain what happened.
"""
Then, we request the LLM to replan:
f"""
Ok, thanks for the explanation. Now, let's replan to the goal from the beginning and avoid this mistake and all previous mistakes.
Currently, these facts are true:
{initial_state_description}
We want these things to be true:
{goal_state_description}
These are the names of the atomic actions that we can perform, along with their descriptions:
{self.action_description_string}
Can you please give a sequence of these phrases that will get us to the goal? Include the exact phrase in each step of your answer. Format it using a numbered list with one line per step, starting with "1.". Give a little explanation of each step underneath each bullet point. Mark the end of the plan with '***' in your response. Please avoid all past planning mistakes.
"""
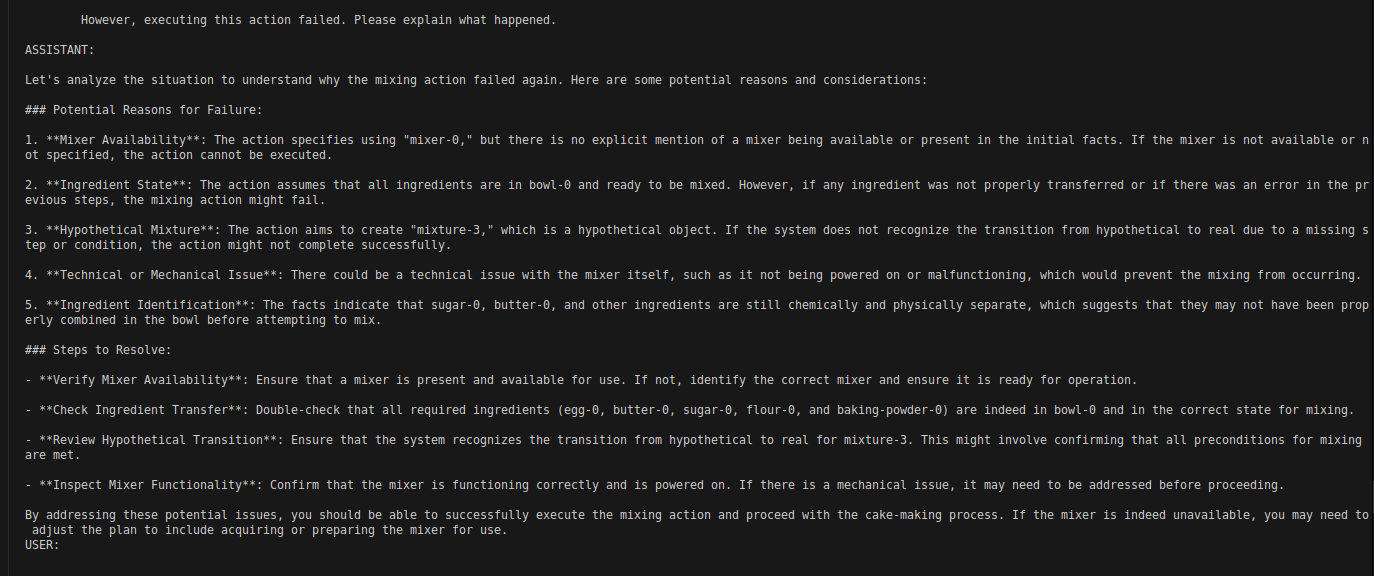
Figure 3: An example failure explanation. GPT4o's response about an execution failure.